![[总结]Postgre经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
[总结]Postgre经验
程序员硬核“年终大扫除”,清理了数据库 70GB 空间 在没有删除单个索引或删除任何数据下,最终释放了超过 70GB 的未优化和未利用的空间,还意外释放 20GB 未使用索引空间。
Just One Pure ITer
程序员硬核“年终大扫除”,清理了数据库 70GB 空间 在没有删除单个索引或删除任何数据下,最终释放了超过 70GB 的未优化和未利用的空间,还意外释放 20GB 未使用索引空间。
1. 背景 几年前我曾经服务过的一家电商公司,随着业务增长我们每天的订单量很快从30万单增长到了100万单,订单总量也突破了一亿。当时用的Mysql数据库。根据监控,我们的每秒最高订单量已经达到了2000笔(不包括秒杀,秒杀TPS已经上万了。秒杀我们有一套专门的解决方案,详见《秒杀系统设计~亿级用户》)。不过,直到此时,订单系统还是单库单表,幸好当时数据库服务器配置不错,我们的系统才能撑住这么大的压力。 业务量还在快速增长,再不重构系统早晚出大事,我们花了一天时间快速制定了重构方案。 重构?说这么高大上,不就是分库分表吗?的确,就是分库分表。不过除了分库分表,还包括管理端的解决方案,比如运营,客服和商务需要从多维度查询订单数据,分库分表后,怎么满足大家的需求?分库分表后,上线方案和数据不停机迁移方案都需要慎重考虑。为了保证系统稳定,还需要考虑相应的降级方案。
SQL连接图解演示-共七页 数据库底层数据结构与数据库索引类型 跳表,哈希索引,SSTable,LSM树,B树,倒排索引,R树,后缀树。 如果MySQL磁盘满了,会发生什么?还真被我遇到了! 要进行磁盘碎片化整理。原因是datafree占据的空间太多,看看自己的系统的datafree大不大 show table status from 表名; 100G内存下,MySQL查询200G大表会OOM么? MySQL中ORDER BY与LIMIT 不要一起用,有大坑 如果order by的列有相同的值时,mysql会随机选取这些行,为了保证每次都返回的顺序一致可以额外增加一个排序字段(比如:id),用两个字段来尽可能减少重复的概率。
MySQL Master/Slave, R/W Seperation
by leelight · Published May 20, 2021 · Last modified November 3, 2022
数据库读写分离的这些坑,让我一脸懵逼! 「由于数据库同步存在延时,这就导致数据同步的这段时间,主从数据将会不一致,从库无法查询到最新的数据。」 最优解:缓存路由大法
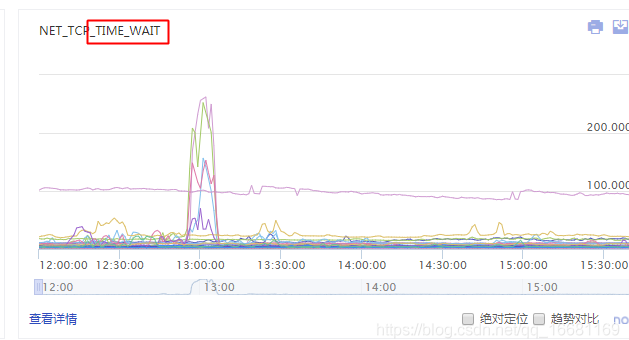
1. 一. 事件背景 我最近运维了一个网上的实时接口服务,最近经常出现Address already in use (Bind failed)的问题。很明显是一个端口绑定冲突的问题,于是大概排查了一下当前系统的网络连接情况和端口使用情况,发现是有大量time_wait的连接一直占用着端口没释放,导致端口被占满(最高的时候6w+个),因此HttpClient建立连接的时候会出现申请端口冲突的情况。
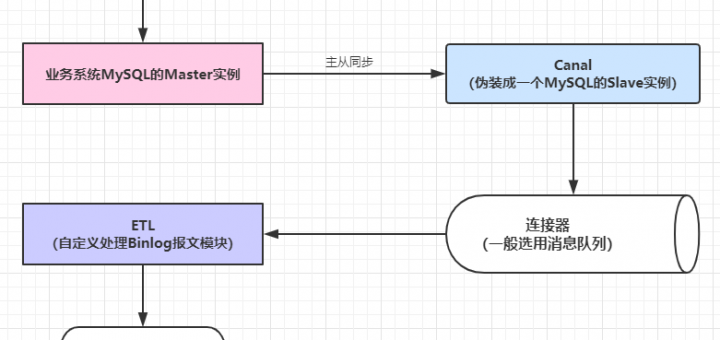
如何基于Canal 和 Kafka,实现 MySQL 的 Binlog 近实时同步? 近段时间,业务系统架构基本完备,数据层面的建设比较薄弱,因为笔者目前工作重心在于搭建一个小型的数据平台。优先级比较高的一个任务就是需要近实时同步业务系统的数据(包括保存、更新或者软删除)到一个另一个数据源,持久化之前需要清洗数据并且构建一个相对合理的便于后续业务数据统计、标签系统构建等扩展功能的数据模型。基于当前团队的资源和能力,优先调研了Alibaba开源中间件Canal的使用。 微服务之数据同步Porter
为什么我们要从MySQL迁移到TiDB? 1.3 万亿条数据查询,如何做到毫秒级响应?TiDB
by leelight · Published September 4, 2019 · Last modified May 20, 2024
Sharding-jdbc教程:Springboot整合sharding-jdbc实现读写分离 Spring Boot集成Sharding-jdbc + Mybatis-Plus实现分库分表 Spring Boot + MyBatis + Druid + PageHelper 实现多数据源并分页 一种基于 MyBatis 框架的分库分表方案!造轮子 分库分表,可能真的要退出历史舞台了! 对于关系型数据库来说,走向分布式也终将成为必然。随着 Raft 等协议应用越来越广泛,分布式数据库的可靠性也逐渐得到了保证。如果你以前因为事务问题而拒绝采用某些 NoSQL 产品,那么如今完全兼容 MySQL 的分布式数据库,你没有理由再说 No。 云厂商,直接提供了像Aurora、PolarDB之类的MySQL增强,更有类似 TiDB、OceanBase 这样纯粹的分布式数据库,越来越多的业务走向了这个终途。当你的团队加班加点验证着分库分表中间件的时候,却发现其实换个兼容的存储就能玩得转,你会怎么选,简直不用再多说。 当然,一旦你选用了分布式数据库,以前的 DBA 经验可能就不管用了,比如说索引及其二级索引。你的团队不得不学习新的知识,来应对分布式环境。...
Database Theory & Solution / Performance Diagnosing
by leelight · Published September 4, 2019 · Last modified April 3, 2020
1. 一、前言 基本上来说,大部分项目都需要跟数据库做交互,那么,数据库连接池的大小设置成多大合适呢? 一些开发老鸟可能还会告诉你:没关系,尽量设置的大些,比如设置成 200,这样数据库性能会高些,吞吐量也会大些! 你也许会点头称是,真的是这样吗?看完这篇文章,也许会颠覆你的认知哦!
[source]日均7亿交易量,如何设计高可用的MySQL架构?
Follow:
![[汇总]端侧模型](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)

| Cookie | Duration | Description |
|---|---|---|
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |