![[转]日订单量达到100万单后,我们做了订单中心重构](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
[转]日订单量达到100万单后,我们做了订单中心重构
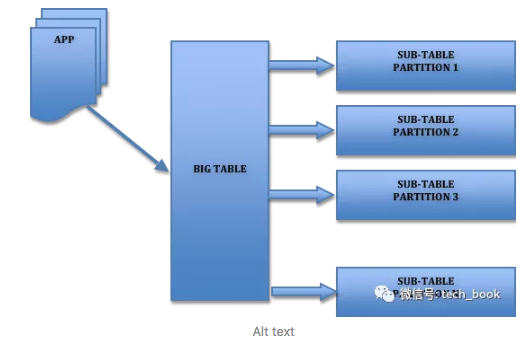
1. 背景 几年前我曾经服务过的一家电商公司,随着业务增长我们每天的订单量很快从30万单增长到了100万单,订单总量也突破了一亿。当时用的Mysql数据库。根据监控,我们的每秒最高订单量已经达到了2000笔(不包括秒杀,秒杀TPS已经上万了。秒杀我们有一套专门的解决方案,详见《秒杀系统设计~亿级用户》)。不过,直到此时,订单系统还是单库单表,幸好当时数据库服务器配置不错,我们的系统才能撑住这么大的压力。 业务量还在快速增长,再不重构系统早晚出大事,我们花了一天时间快速制定了重构方案。 重构?说这么高大上,不就是分库分表吗?的确,就是分库分表。不过除了分库分表,还包括管理端的解决方案,比如运营,客服和商务需要从多维度查询订单数据,分库分表后,怎么满足大家的需求?分库分表后,上线方案和数据不停机迁移方案都需要慎重考虑。为了保证系统稳定,还需要考虑相应的降级方案。
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)
