[repost]Diagnosing Common Database Performance Hotspots in our Java Code
When I help developers or architects analyze and optimize the performance of their Java application it is not about tweaking individual methods to squeeze out another millisecond or two in execution time. While for certain software it is important to optimize on milliseconds I think this is not where we should start looking. I analyzed hundreds of applications in 2015 and found most performance and scalability issues around bad architectural decisions, misconfigured frameworks, bad database access patterns, excessive logging and exhaustive memory usage leading to garbage collection impact.
For me, performance engineering has more to do with observing and correlating key architectural, scalability and performance metrics over time, from build-to-build and under different load conditions, to identify regressions or bottlenecks. Take the following dashboard as an example:
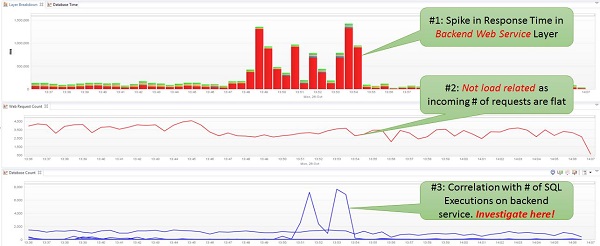
Correlating Load with Response Time and # SQL Executions answers several performance engineering root cause questions!
The top graph is called a “Layer Breakdown” chart and shows total execution time of your application split by logical components (Web Services, Database Access, Business Logic, Web Server, …). RED indicates time spent in one of the Backend Web Services. So we have a clear component hotspot. We also know that the web service is not under unusual load as the second chart shows a flat line for # of Requests processed by the application. A common finding is that most of the overall response time is spent in the database tier. However, that does not necessarily mean that the database itself is slow! Knowing that inefficient database access is very often the reason for bad performance, I always correlate the # of SQL Executions. In this case there is a clear visual correlation for most parts of the response time spike.
Bad Database Access Patterns is the one problem pattern I observe most often, followed by service calls that are too chatty, bad shared data access synchronization, excessive logging, and memory leaks/high object churns resulting in garbage collection impact or application crashes.
1. Available diagnostics tools
For this article I focus on the database as I am sure all of your apps are suffering from one of these access patterns! You can use pretty much any profiling, tracing or APM tool available in the market, but I am using the free Dynatrace Personal License. Java also comes with great tools such as Java Mission Control. Many frameworks that access data – such as Hibernate or Spring – also offer diagnostics options typically through logging output.
Using these tracing tools doesn’t require any code changes as they all leverage JVMTI (JVM Tooling Interface) to capture code level information and even to trace calls across remoting tiers. This is very useful in distributed, (micro)service-oriented applications; just modify your startup command line options for your JVM to get the tools loaded. Some tool vendors provide IDE integration where you can simply say “run with XYZ Profiling turned on”. I have a short YouTube tutorial demonstrating how to trace an app launched from Eclipse!
2. Identify Database Performance Hotspots
When it turns out that the database is the main contributor to the overall response time of requests to your application, be careful about blaming the database and finger pointing at the DBAs! There might be several reasons that would cause the database to be that busy:
- Inefficient use of the database: wrong query design, poor application logic, incorrect configuration of data access framework
- Poor design and data structure in the database: table relations, slow stored views, missing or wrong indexes, outdated table statistics
- Inappropriate database configuration: memory, disk, tablespaces, connection pools
In this article I mainly want to focus on what you can do from the application side to minimize the time spent in the database:
3. Diagnose Bad Database Access Patterns
When diagnosing applications I have several database access patterns I always check for. I look at individual requests and put them into the following DB Problem Pattern categories:
- Excessive SQLs: Executing a lot (> 500) different SQL Statements
- N+1 Query Problem: Executing the same SQL statement multiple times (>20):
- Slow Single SQL Issue: Executing a single SQL that contributes > 80% of response time
- Data-Driven Issue: Same request executes different SQL depending on input parameters
- Database Heavy: Database Contribution Time is > 60% of overall response time
- Unprepared Statements: Executing the same SQL without preparing the statement
- Pool Exhaustion: Impacted by High Connection Acquisition Time (getConnection time > executeStatement)
- Inefficient Pool Access: Excessive access to connection pool (calling getConnection > 50% of executeStatement count)
- Overloaded Database Server: Database server is simply overloaded with too many requests from different apps
Example #1: Excessive SQL in Home Grown O/R Mapper
The first sample I have is from a web application that provides an overview of meeting rooms in a particular building. The meeting room information is stored in a database and accessed through a custom data access layer every time someone generates that report.
I always start by looking at the so called Transaction Flow when analyzing individual requests. The Transaction Flow is a visualization option showing how requests are processed by the application. For our meeting room overview report we can see the request entering on the web server tier (left), continuing into the app server tier (middle) and making calls to the database tier (right). The “links” between these tiers show how many interactions there are between these tiers, e.g: how many SQL queries are executed by this single request.
This screen immediately identifies the first two patterns to rear their ugly heads; namely the Excessive SQLs pattern as well as the Database Heavy pattern. Let’s take a look:
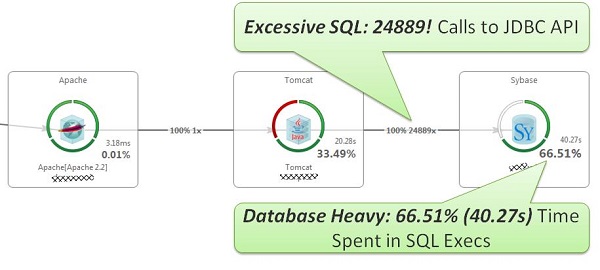
Easy to Spot Excessive SQL Executions + Database Heavy: 24889 SQLs! Taking 40.27s (66.51% of overall time) to execute!
Looking at the individual SQLs reveals that this request also suffers from the N+1 Query Problemas well as the Inefficient Pool Access (more on this below):

Bad Access Patterns like this can’t be solved by optimizing indices beefing up the database machines.
I see this problem all too often; the application logic iterates through a list of objects but instead of loading that data “eagerly”, a “lazy load” approach is chosen, either in the O/R Mapping Framework such as Hibernate/Spring, or in self-coded frameworks as in the example above. The example above used a home-grown implementation that loads every meeting room object and then fetches all properties for each room through individual SQL queries. Each of those SQL queries was executed on a separate JDBC connection that was acquired from the pool, then executed, and then returned after each query completed. That explains the 12444 calls to set clientname that got submitted by the Sybase JDBC driver every time a connection was acquired from the pool. Booom! For other JDBC drivers that may not make that set clientname call, you can simply have a look at how often you call getConnection, which provides the same insights.
And for the N+1 query problem itself: it can easily be avoided by using joined queries. In our room and properties example that could look like:
The result is the execution of 1 query instead of more than 12000! And 12000 less connection acquisitions and “set clientname” calls.
Example #2: Excessive SQL with wrong Hibernate Configuration
As I know that many use Hibernate or other O/R mappers I want to remind you that there are good reasons O/R mappers offer lazy vs. eager loading options as well as several layers of caching. Be sure to use these features and options correctly for your specific use case.
The following is an example where lazy loading was not a great choice, since loading 2k objects and their properties resulted in 4k+ SQL queries. Considering that all objects would always be needed, it would have been better to eager load these objects and then think about caching them, assuming they don’t change very frequently:
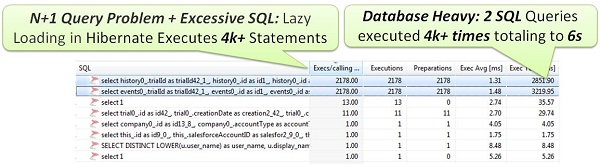
Choose the correct loading and caching options when using O/R Mappers like Hibernate & Spring. Understand what they are doing behind the scene
Most O/R mappers provide good options for diagnostics through logging. Also check their online communities for best practices. A blog series I can recommend is from Alois Reitbauer who did extensive research in the early days of Hibernate to highlight how to efficiently use Caching and Loading Options.
Example #3: Unprepared Statements in custom DB Access Code
After a SQL statement is parsed by the database engine and the execution plan for data access is created, that result is stored in a cache area in the database to be used again without the need to re-parse the statement (which consumes most of the CPU time in the database). The key that is used to find a query in the cache is the full text of the statement. That means, if you have the same statement 1000 times with 1000 different parameter values (like for a where clause), there are 1000 different entries in the cache. Query No 1001 with a new parameter has to be parsed again. This is very inefficient. Therefore, we have the concept of “Prepared Statements”: a query is prepared, parsed and stored in the cache with placeholders for variables. For the real execution of the statement they are replaced by real values. But there is no need to re-parse the statement, the execution plan can be taken from the cache.
Database access frameworks are typically smart enough to prepare statements, but in custom code I often see that developers are negligent such as in the following example where only a small fraction of SQL executions were actually prepared:

Watch out for unprepared database access by comparing # of SQL Executions and # of Prepared SQL Executions
If you develop your own code, double check that you are calling prepareStatement as appropriate. For example, if you are calling a query more than once, it is generally best to use a PreparedStatement. If you use frameworks to access data, always double check what these frameworks are doing and what configuration options are provided for optimizing and executing the generated SQL. The easiest approach for that is to monitor the number of times executeStatement vs. prepareStatement gets executed. If you do that for each SQL query you can easily locate your optimization hotspots.
Example #4: Inefficient Pool Sizing for protracted back end SQL reports
I often see apps that run with the default connection pool size of 10 or 20 connections per pool. All too often, developers don’t feel the need to optimize pool size as they typically don’t do the requisite large scale load testing, nor do they know how many users will be expected to use that new feature, or what ramifications it implies, for parallel DB Access. Or perhaps the pool configuration “got lost” along the way from pre-prod to production deployment and then defaulted back to whatever the default is for your app server.
Connection pool utilization can easily be monitored through JMX metrics. Every application server (Tomcat, JBoss, WebSphere, …) exposes these metrics, although some require you to explicitly enable this feature. The following shows the pool utilization of four WebLogic servers running in a cluster. You can see that “Number of Active DB Connection” is reaching a maximum for three of the app servers:
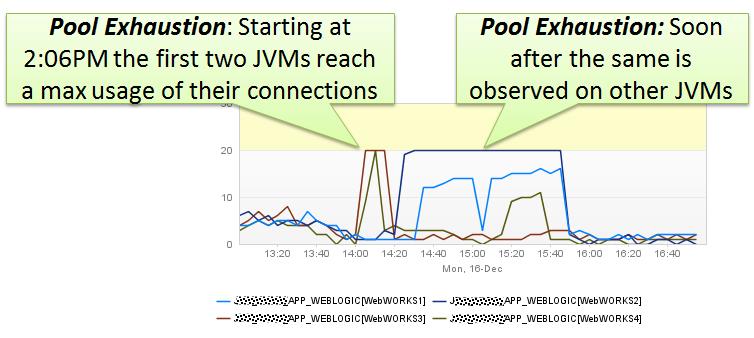
Make sure you properly size your connection pools and don’t run with default settings that are not aligned with your expected load behavior
The root cause of this problem was not a spike in overall traffic. Using my Load vs. Response Time vs. Database Count dashboard from the beginning of this article showed me that there was no extra traffic spike. It turned out that they had scheduled reports running shortly after 2PM daily, that executed several very long-running UPDATE statements – all on different connections. That blocked all the connections for several minutes and caused the “normal” traffic to run into performance issues, since these requests couldn’t get any connections to the database:

Individual SQLs executed blocked several connections for several minutes leading to the connection pool exhaust issue
If you know that you have certain requests that hold on to connections for an extended duration, you should either:
- put them on separate servers so as not impact anybody else,
- schedule them at a time when nobody will be impacted, or
- increase the connection pool size to have enough connections available for the regular traffic.
But at first make sure to optimize these queries. Analyze the SQL query execution plans to identify where the time is currently spent. Most of the modern APM tools these days give you the option to retrieve the execution plan for a SQL statement.. If that’s not available, the easiest way is to use your database’s command line tool, or just consult a DBA to generate it for you.
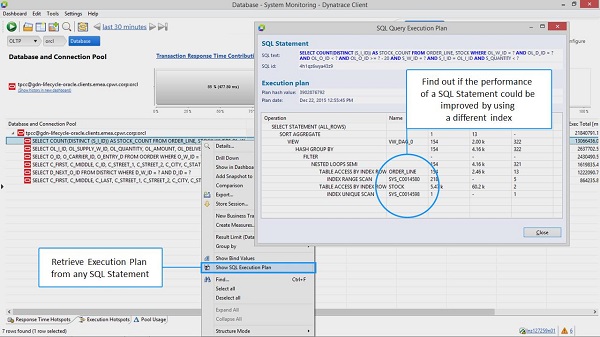
Optimize your SQL statements by learning from the SQL Query Execution Plan
The execution plan shows how the SQL statement is processed by the DB engine. Reasons for slow SQL can be various. It’s not only missing or incorrect use of indexes, but many times the design and structure or joined queries. If you are not a SQL expert reach out to your DBAs or SQL gurus for this critical assistance.
4. Load Test and Production Monitoring Tips and Tricks
Besides looking at individual requests and identify these patterns I also look at long term trends when an application is under load. Besides the dashboard I showed you in the very beginning I also identify data driven behavior changes and verify if data caches work correctly.
Check #1: Access to DB should decrease due to the help of Data Caches
The following shows a dashboard charting Average Number of SQL Executions (green) vs Total Number of SQL Executions (blue). In a constant high load performance test run over a period of two hours I am expecting the average number to slightly decrease and the total curve to flatten. Why? Because I assume that most of the data we get from the DB is static or will be cached in a different layer:
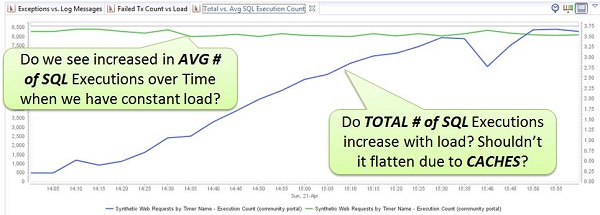
If your app behaves differently you might have a data driven performance problem or a problem with your caches
If you have a classic N+1 Query Problem in your app – as I showed you earlier – then as more data is added to the DB by your end users producing data, your app will show an increase in the average number of SQLs, since more data will be returned in those queries! So – better watch those numbers!
Check #2: Identify SQL Access Pattern by Type
Similar to the case above in Example #4, where the background report was kicked off at 2PM, I am always looking for patterns of overall SQL accesses over time. I look at Total Execution Time, but also Execution Count of SELECT, INSERT, UPDATE and DELETE. This allows me to identify if there are certain times during the day when some special activity is going on such as background jobs updating large sets of data.
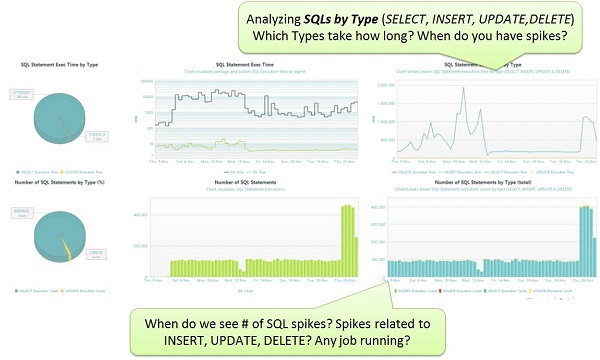
Learn database access behaviors of your app by looking at Total Time and Execution Count of SELECT, INSERT, UPDATE and DELETE
Batch jobs performing mass updates may take a while, especially for tables with a huge number of rows. If the entire table is locked for that purpose, be aware that other requests performing updates on that table, even on single rows, have to wait until the lock is released. Consider running these jobs at times when no other users are online, or implement a different locking logic to lock, update and release row by row.
Check #3: How is the Database Instance Doing?
In this article I have tried to emphasize that database performance problems are most often NOT related to a slow database server, but more likely to the application code that has bad database access patterns (N+1 Query Problem, Unprepared Statements, …) or configuration Issues (Inefficient Pool Access, Data-Driven Issues, …).
But it would be unwise to completely ignore the database, and so I always like to check the key database performance metrics. Most databases provide excellent performance information via special system tables; for example Oracle provides several v$ tables and views to access key database performance metrics (# Sessions, Wait Times, Time Spent in Parse, Execution …) or information such as Table Locks or slow SQLs coming in from all sorts of applications that use that shared database instance.
Here are two dashboards I look at for a quick sanity check. You can see the metrics that are pulled from exactly these performance tables:
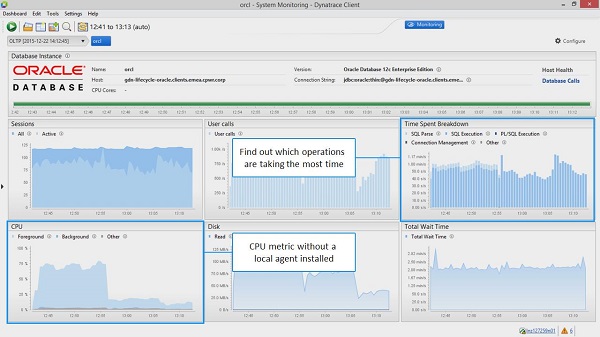
Find out whether the database is healthy or might be impacted by too much load from all applications that share this database instance.
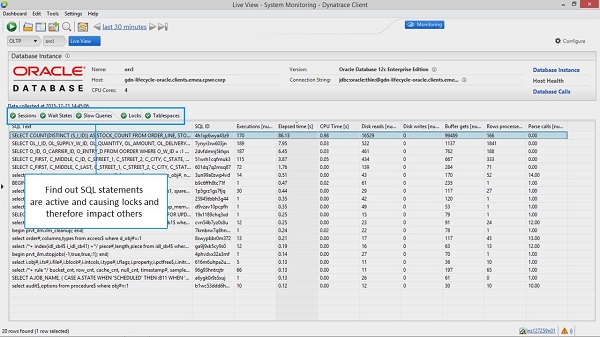
Check out whether any of the currently executing SQLs is impacting the server and therefore your app, e.g: through table locks
5. Automate DB Metrics Check in Continuous Integration
Before I leave you with an array of new ideas about key database metrics and use cases, I want to bridge the gap to a topic that we should all be thinking about: Automation!
Instead of doing all of these checks manually, I propose to look at these metrics in your continuous integration tool while executing your unit, integration, REST API or any other type of functional test. If you’ve already invested in a test suite that verifies the functionality of your new REST API or your new cool feature, then why not capture these metrics for every test execution on every build? Such an approach would provide the following benefits:
- Code reviews that focus on these metrics, rather than trawling through every line of code
- Notifications on code check-ins that introduce any of these behaviors
Here is a screenshot of tracking these metrics for every test and every build and alert when there is a change in behavior. Integrate this with your build pipeline and get notified in case a code change had a bad impact – then fix it right away instead of waiting for a crashing system when it is released in production:

Put these metrics into your Continuous Integration and automatically identify these patterns by watching out for changed metric behavior!
6. There is so much more than database
In this article we have focused on database related hot-spots. But in my work I also see many problems in other areas as well. In 2015 I saw a huge spike in problems around monolith to (micro)service migration projects, and similar patterns to what we saw here, such as the N+1 Query problem, where a backend service gets called hundreds of times per use case invocation. Most of the time the issues are due to bad interface design, and failing to consider what will happen when a once local method gets executed in your Docker containers or in a cloud environment. The network all of a sudden comes into play, including the payload you put on it as well as new connection pools (thread and sockets) that you have to deal with. But that is a story for another day. Stay tuned and “May the metrics be with you” 
In our next article we will cover Locating Common Micro Service Performance Anti-Patterns.
[source]Diagnosing Common Database Performance Hotspots in our Java Code
![[转]数据库连接池的大小与性能](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
![[汇总]端侧模型](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)






