Category: Database Partitioning&Scaling
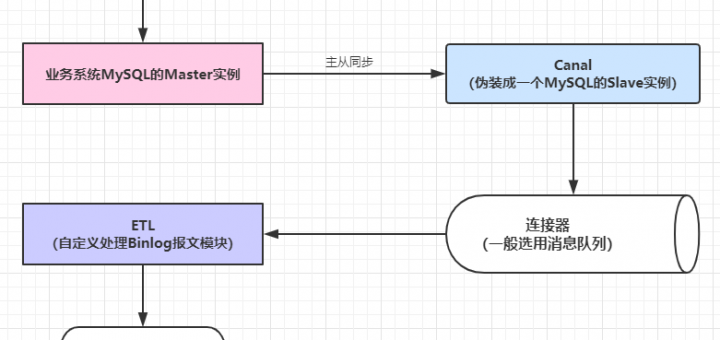
如何基于Canal 和 Kafka,实现 MySQL 的 Binlog 近实时同步? 近段时间,业务系统架构基本完备,数据层面的建设比较薄弱,因为笔者目前工作重心在于搭建一个小型的数据平台。优先级比较高的一个任务就是需要近实时同步业务系统的数据(包括保存、更新或者软删除)到一个另一个数据源,持久化之前需要清洗数据并且构建一个相对合理的便于后续业务数据统计、标签系统构建等扩展功能的数据模型。基于当前团队的资源和能力,优先调研了Alibaba开源中间件Canal的使用。 微服务之数据同步Porter
Sharding-jdbc教程:Springboot整合sharding-jdbc实现读写分离 Spring Boot集成Sharding-jdbc + Mybatis-Plus实现分库分表 Spring Boot + MyBatis + Druid + PageHelper 实现多数据源并分页 一种基于 MyBatis 框架的分库分表方案!造轮子 分库分表,可能真的要退出历史舞台了! 对于关系型数据库来说,走向分布式也终将成为必然。随着 Raft 等协议应用越来越广泛,分布式数据库的可靠性也逐渐得到了保证。如果你以前因为事务问题而拒绝采用某些 NoSQL 产品,那么如今完全兼容 MySQL 的分布式数据库,你没有理由再说 No。 云厂商,直接提供了像Aurora、PolarDB之类的MySQL增强,更有类似 TiDB、OceanBase 这样纯粹的分布式数据库,越来越多的业务走向了这个终途。当你的团队加班加点验证着分库分表中间件的时候,却发现其实换个兼容的存储就能玩得转,你会怎么选,简直不用再多说。 当然,一旦你选用了分布式数据库,以前的 DBA 经验可能就不管用了,比如说索引及其二级索引。你的团队不得不学习新的知识,来应对分布式环境。...
[source]日均7亿交易量,如何设计高可用的MySQL架构?
1. 正常情况下的服务演化之路 让我们从最初开始。 1-1. 1、单体应用 每个创业公司基本都是从类似 SSM 和 SSH 这种架构起来的,没什么好讲的,基本每个程序员都经历过。 1-2. 2、RPC 应用 当业务越来越大,我们需要对服务进行水平扩容,扩容很简单,只要保证服务是无状态的就可以了,如下图: 当业务又越来越大,我们的服务关系错综复杂,同时,有很多服务访问都是不需要连接 DB 的,只需要连接缓存即可,那么就可以做成分离的,减少 DB 宝贵的连接。如下图: 我相信大部分公司都是在这个阶段。Dubbo 就是为了解决这个问题而生的。 1-3. 3、分库分表 如果你的公司产品很受欢迎,业务继续高速发展,数据越来越多,SQL 操作越来越慢,那么数据库就会成为瓶颈,那么你肯定会想到分库分表,不论通过 ID hash 或者 range 的方式都可以。如下图: 这下应该没问题了吧。任凭你用户再多,并发再高,我只要无限扩容数据库,无限扩容应用,就可以了。 这也是本文的标题,分库分表就能解决无限扩容吗? 实际上,像上面的架构,并不能解决。 其实,这个问题和...
为什么需要研究跨库分页? 互联网很多业务都有分页拉取数据的需求,例如: (1)微信消息过多时,拉取第N页消息; (2)京东下单过多时,拉取第N页订单; (3)浏览58同城,查看第N页帖子;
1. 一、前言 中大型项目中,一旦遇到数据量比较大,小伙伴应该都知道就应该对数据进行拆分了。有垂直和水平两种。
1. 如何部署 1-1. 停机部署法 大致思路就是,挂一个公告,半夜停机升级,然后半夜把服务停了,跑数据迁移程序,进行数据迁移。
任何看到显著增长的应用程序或网站,最终都需要进行扩展。以适应流量的增加和确保数据安全性和完整性的方式进行扩展,对于数据驱动的应用程序和网站来说十分重要。人们可能很难预测某个网站或应用程序的流行程度,也很难预测这种流行程度会持续多久——这就是为什么有些机构选择“可动态扩展的”数据库架构的原因。 本文将讨论一种“可动态扩展的”数据库架构:分片数据库。
分布式是如何进入数据库领域的? 我曾经访问过一个有“营业时间”的网站,它只在某些时间段才“开放”。我因此感到困惑,还有点沮丧。计算机可以运行一整天,为什么这个网站就不可以呢?可能我已经习惯了互联网那种令人难以置信的可用性保证。 然而,在互联网出现之前,全天候可用性的概念还“不成气候”。可用性虽然令人期待,但还没有到非要不可的程度。我们只在有需要时才使用电脑,它们不会为了一个极小可能出现的请求而等待。随着互联网的出现和发展,之前不太常见的本地凌晨 3 点请求变成了全球性的主要营业时间点,确保计算机能够处理这些请求就变得非常重要。
技术人如果经常线上操作DB,河边走久了,难免出现纰漏: update错数据了 delete错数据了 drop错数据了 咋办?找DBA恢复数据呗,即使恢复不了,锅总得有人背呀。 画外音:把数据全删了,怎么办,怎么办?
![[汇总]分库分表经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)
