![[转]架构师不是管理者,是领导者](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
[转]架构师不是管理者,是领导者
俗话说:不想当架构师的程序员不是好程序员。成为架构师,几乎是每位开发者入行初期的共同理想。但架构师并非只是一个单纯的技术岗位,它需要技术能力与综合能力的共同支持。了解架构师的职业定位与主要职责,掌握架构师所需的核心技能,是通往这一高阶职位道路上的必修课。
Just One Pure ITer
俗话说:不想当架构师的程序员不是好程序员。成为架构师,几乎是每位开发者入行初期的共同理想。但架构师并非只是一个单纯的技术岗位,它需要技术能力与综合能力的共同支持。了解架构师的职业定位与主要职责,掌握架构师所需的核心技能,是通往这一高阶职位道路上的必修课。
项目经理有80%甚至更多的时间都用于进行项目的沟通工作,可以说沟通是每个项目经理一生的功课,而会不会说话,也成为评判一个项目经理沟通能力高低的重要指标。 如何跟别人沟通? 如何让谈话更有效果? 如何避免成为”话题杀手”? 下面这十个技巧一定会对你有所帮助!
We got escalation today, a lot of services are very slow or stop working. Our Oracle database(10g) admin has found that there are a huge number of unclosed sessions in the Oracle database. In...
In Jenkins configuration the following configs have been set: Maven Project Configuration->Global MAVEN_OPTS
|
1 |
-Xmx8192m -XX:MaxPermSize=1024m |
Global properties->Environment variables
|
1 2 3 4 |
Name: MAVEN_OPTS Value: -Xmx8192m -XX:MaxPermSize=1024m -Djava.io.tmpdir=/clusters/shared_workspace/tmp |
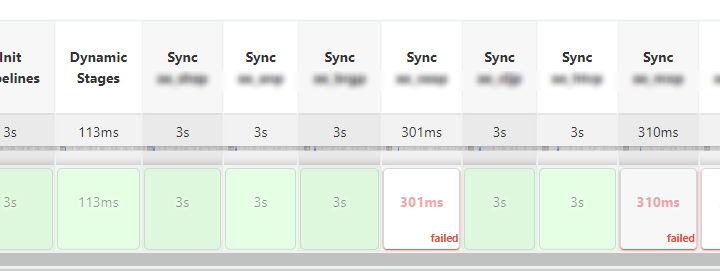
There is a requirement from the customer, to build a pipeline, which will be executed to call 100 remote entry points. Of course, we have a classic approach to do this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
stage('aa_11'){ steps{ build job: 'Tasks/pipeline_to_call_remote_api', wait: true, parameters: [ string(name: 'PARAM1', value: 'aa'), string(name: 'PARAM2', value: '11') ] } } stage('aa_22'){ steps{ build job: 'Tasks/pipeline_to_call_remote_api', wait: true, parameters: [ string(name: 'PARAM1', value: 'aa'), string(name: 'PARAM2', value: '22') ] } } ....... |
In Kubernetes, the Liveness and Readiness Kubernetes concepts represent facets of the application state. The Liveness state of an application tells whether the internal state is valid. If Liveness is broken, this means that the application...
认真读完这 100 条建议,你一定会有所收获。
Edouard Thomas 开发的一个类似的 开源 AI 博彩机器人项目(https://github.com/edouardthom/ATPBetting) 名为 freqtrade (https://github.com/freqtrade/freqtrade)的开源交易机器人。它使用 Python 构建,并实现了多种机器学习算法 人脸识别库(https://pypi.org/project/face-recognition/),并将其与摄像头的输出连接起来。
数据权限这样设计 RBAC是Role-BasedAccess Control的英文缩写,意思是基于角色的访问控制。
2000 年,Robert C. Martin 给架构师们总结出了一套原则来指导大家进行软件设计,Michael Feathers 随后按首字母将其总结成 SOLID 原则。从那时起,面向对象的 SOLID 设计原则就不断出现在相关书籍当中,并成为业界广为人知的指导方针:单一职责原则、开 / 闭原则、里氏替换原则、接口隔离原则、依赖倒置原则。 Single responsibility principle Open/closed principle Liskov substitution principle Interface segregation principle Dependency inversion principle 在过去的这二十年里,软件开发领域一直在快速演进,特别是近几年云原生和微服务的发展,在微服务体系下,“SOLID 原则是否适合现代软件工程”引起了广泛讨论。
Follow:
![[汇总]AI经验](http://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)

| Cookie | Duration | Description |
|---|---|---|
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |