Mobabel Blog
![[汇总]面试经验](https://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
[转]从 0 到 1 再到 100, 搭建、编写、构建一个前端项目
1. 1. 选择现成的项目模板还是自己搭建项目骨架 搭建一个前端项目的方式有两种:选择现成的项目模板、自己搭建项目骨架。 选择一个现成项目模板是搭建一个项目最快的方式,模板已经把基本的骨架都搭建好了,你只需要向里面填充具体的业务代码,就可以通过内置的工具与命令构建代码、部署到服务器等。
[转]Flink如何取代JStorm,成为字节跳动流处理唯一标准?
本文主要内容包括: 引入 Apache Flink 的背景 Apache Flink 集群的构建过程 构建流式管理平台 近期规划

[转] du & df
今天有个实习生问了我一个诡异的问题,“线下一台磁盘大小32G的开发机(虚拟机)打不出日志”,把追查过程和大家分享一下。 画外音:贵司开发机磁盘容量多大? 先du一下,查看磁盘空间: [shenjian@dev02 ~]# du -sch /16G / 画外音:似乎还有空间。 再试了一下df,发现结果不一样: [shenjian@dev02 ~]$ df -h文件系统 容量 已用 可用 已用% 挂载点/dev/sda2 33G 33G 33G 100% //dev/sda1 ...
[转]如何用Zipkin做好分布式追踪?
现代微服务架构由于业务系统模型日趋复杂,分布式系统中需要一套链路追踪系统来帮助我们理解系统行为,明确服务间调用。最近作者请到了 Zipkin 项目的主要开发维护人员 Adrian Cole 来介绍有关 Zipkin 项目的细节内容,可以让大家了解到如何在分布式追踪系统中用好 Zipkin。Adrian 一直在从事云计算相关开源项目的开发,是开源项目 Apache jclouds 和 OpenFeign 的创始人。最近几年,他专注于分布式跟踪领域,是 OpenZipkin 项目的主要开发维护人员。Adrian 目前在 Pivotal Spring Cloud OSS 团队工作。在加入 Pivotal 之前,他还在 Twitter,Square,Netflix 工作过。
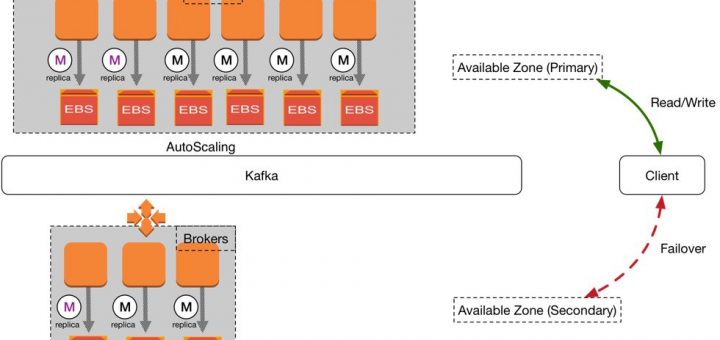
[转]FreeWheel日均10亿日志场景下的高可用实践
1. 写在前面 近几年互联网服务安全事故的频发,使得越来越多的企业及开发者意识到数据备份、灾备等重要性,高可用性、高容灾性及高可扩展性的系统和架构建设工作也被更多地置于重心。 在这个过程中,基于公有云提供的基础设施实现高可用已成为多数技术团队的选择。
[转]关于MySQL内核,一定要知道的!
近一个多月,写了一些MySQL内核的文字,稍作总结,希望对大家有帮助。 1.《InnoDB,为何并发如此之高?》 文章介绍了: (1)什么是并发控制; (2)并发控制的常见方法:锁,数据多版本; (3)redo,undo,回滚段的实践; (4)InnoDB如何利用回滚段实现MVCC,实现快照读。 结论是,快照读(Snapshot Read),这种不加锁的读,是InnoDB高并发的核心原因之一。 番外篇:《快照读,在RR和RC下的差异》 快照读,在可重复读与读提交两种事务隔离级别下,有微小的差异,文章通过案例做了简单叙述。
[转]德国职场如何讲故事
我只能讲讲职场中的故事,因为我在德国的企业里混了20多年。华人圈里经常讨论,为什么很多印度人能做到世界500强企业的高管位置,华人却默默无闻。与印度人相比,华人在外企里相对而言不是很会讲故事,今天我们就来讲讲如何讲好一个故事。其实你每天都在讲故事,和老板讨论项目是在讲故事,要求升职加薪也是在讲故事。朱导讲怎么将现实生活变成艺术故事,我来讲讲怎么将艺术故事返回现实。
![[汇总]端侧模型](https://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)
