Mobabel Blog
![[转]分布式事务,原来可以这么玩?](https://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-medium-empty.png)
[转]FreeWheel业务系统微服务化过程经验分享
2016 年下半年开始,FreeWheel 开始将其业务系统从 Rails 单体应用逐步迁移到微服务,同时技术栈从 Rails 改为 Golang,两年之后,整个迁移接近尾声,FreeWheel 业务系统技术团队对外分享了它们在微服务化过程中的经验。
[转]比拼Kafka,大数据分析新秀Pulsar到底好在哪
AI 前线导读: 一年一度由世界知名科技媒体 InfoWorld 评选的 Bossie Awards 于 9 月 26 日公布,本次 Bossie Awards 评选出了最佳数据库与数据分析平台奖、最佳软件开发工具奖、最佳机器学习项目奖等多个奖项。在 最佳开源数据库与数据分析平台奖 中,之前曾连续两年入选的 Kafka 意外滑铁卢落选,取而代之的是新兴项目 Pulsar。 Bossie Awards 中对 Pulsar 点评如下:“Pulsar 旨在取代 Apache Kafka 多年的主宰地位。Pulsar 在很多情况下提供了比 Kafka 更快的吞吐量和更低的延迟,并为开发人员提供了一组兼容的 API,让他们可以很轻松地从 Kafka 切换到 Pulsar。Pulsar 的最大优点在于它提供了比 Apache Kafka...
[转]看下资深架构师平时需要解决的问题,对比你离资深架构师还有多少距离——再论技术架构的升级之路
我目前奋力在技术架构的路上不断前行,虽然中间遇到很多障碍,目前自己感觉,勉强能达到架构师的级别,所以自己感觉还有底气写这篇文章。 之前,我写过篇博文,架构师更多的是和人打交道,说说我见到和听说到的架构师升级步骤和平时的工作内容,这篇文章更多的是从沟通角度分析架构师的升级之道。但我们知道,架构师更多是靠技术拿高薪。 在本文里,我将列些我见到的技术架构平时需要解决的问题,有技术的,也有沟通协调方面的,以这些实实在在的案例,来列举些技术架构需要具备的技能,以此来分析下高级开发如何更高效地升级到技术架构。好了,开场白结束,正文开始。
[转]Kafka如何做到1秒处理1500万条消息?
一位软件工程师将通过本文向您呈现 Apache Kafka 在大型应用中的 20 项最佳实践。 Apache Kafka 是一款流行的分布式数据流平台,它已经广泛地被诸如 New Relic(数据智能平台)、Uber、Square(移动支付公司)等大型公司用来构建可扩展的、高吞吐量的、且高可靠的实时数据流系统。 例如,在 New Relic 的生产环境中,Kafka 群集每秒能够处理超过 1500 万条消息,而且其数据聚合率接近 1Tbps。 可见,Kafka 大幅简化了对于数据流的处理,因此它也获得了众多应用开发人员和数据管理专家的青睐。
[转]高并发的三个经典问题
1、单台服务器最大并发 单台服务器最大并发问题,一般是指一台服务器能够支持多少 TCP 并发连接。 一种理论说法是受到端口号范围限制。操作系统上端口号 1024 以下是系统保留的,从 1024-65535 是用户使用的。由于每个 TCP 连接都要占一个端口号,所以我们最多可以有 60000 多个并发连接。 但实际上单机并发连接数肯定要受硬件资源(内存、网卡)、网络资源(带宽)的限制。特别是网卡处理数据的能力,它是最大并发的瓶颈。
[转]三种系统监控工具对比:top vs Htop vs Glances
在开发软件或监控运行的系统时,遥测和环境监测都很重要。以便了解系统的运行状况,本文介绍了 top、Htop、Glances 三个实用工具,以及一种用于监控分布式系统的简单解决方案。 在开发软件或监控运行的系统时,遥测和环境监测都很重要。在理解了历史情境下什么是正常行为之后,通常两个最紧迫的问题是:(1)什么发生了变化?(2)什么表现出异常? 本文将介绍三个用于临时监控的流行工具,以及一种用于监控分布式系统的简单解决方案。
[转]程序员的管理思维修炼
一个技术精湛的程序员,只要有机会,就有可能被公司提拔为项目管理人员,掌控项目中的一切。 但所谓权力越大责任越大,要想成为一个合格的项目管理人员,我认为最重要的首先是扭转自己的思想。 正如老子说的“道为体,术为用。”我们的思维模式改变了,各种管理的方法和工具自然的就会去学习使用了。 正所谓“有道者术能长久,无道者术必落空。”所以在本文中,我就和大家聊一聊管理中的“道”,我们程序员如何修炼管理思维?我们要先懂得道理,再去学怎么做。
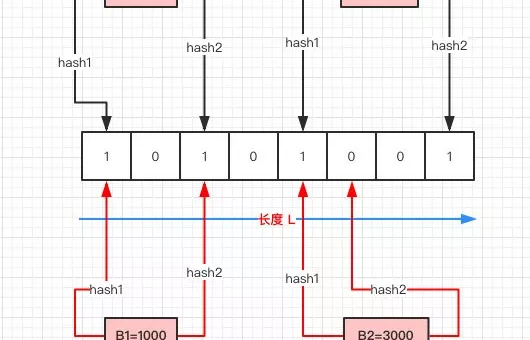
[转] Bloom Filter 如何判断一个元素在亿级数据中是否存在?
1. 前言 最近有朋友问我这么一个面试题目: 现在有一个非常庞大的数据,假设全是 int 类型。现在我给你一个数,你需要告诉我它是否存在其中(尽量高效)。 需求其实很清晰,只是要判断一个数据是否存在即可。 但这里有一个比较重要的前提:非常庞大的数据。
![[汇总]端侧模型](https://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)
