[转]业务越来越复杂,领域驱动如何在业务开发中落地?
最近一段时间,领域驱动和微服务受到了越来越多的关注。对于互联网从业者来说,业务会变得越来越复杂,这时候就需要一些系统的方法论来指导开发实现,目前业界关注比较多的方法论就是领域驱动。那么,领域驱动如何应用到具体的项目中?在项目过程中需要注意哪些问题?
Just One Pure ITer
最近一段时间,领域驱动和微服务受到了越来越多的关注。对于互联网从业者来说,业务会变得越来越复杂,这时候就需要一些系统的方法论来指导开发实现,目前业界关注比较多的方法论就是领域驱动。那么,领域驱动如何应用到具体的项目中?在项目过程中需要注意哪些问题?
Redis High Avaliable Scale Architect
by leelight · Published September 19, 2018 · Last modified December 16, 2018
知乎作为知名中文知识内容平台,每日处理的访问量巨大,如何更好的承载这样巨大的访问量,同时提供稳定低时延的服务保证,是知乎技术平台同学需要面对的一大挑战。 知乎存储平台团队基于开源 Redis 组件打造的 Redis 平台管理系统,经过不断的研发迭代,目前已经形成了一整套完整自动化运维服务体系,提供一键部署集群,一键自动扩缩容,Redis 超细粒度监控,旁路流量分析等辅助功能。
Cache in distributed Architecture
by leelight · Published September 19, 2018 · Last modified June 6, 2022
1. 0 背景 在之前的文章中缓存进化史介绍了某大型互联网公司的缓存架构和缓存的进化历史。俗话说得好,工欲善其事,必先利其器,有了好的工具肯定得知道如何用好这些工具,本篇将介绍如何利用好缓存。
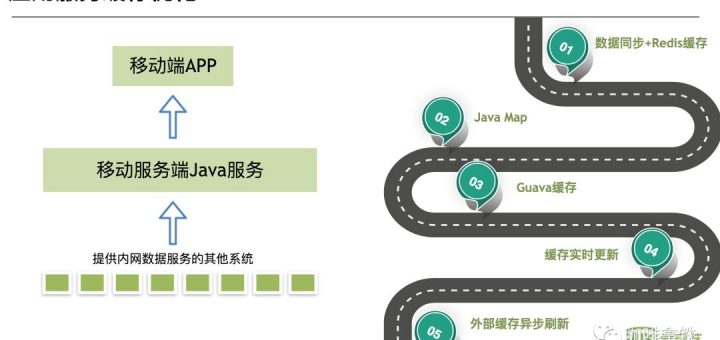
1. 1 背景 本文是上周去技术沙龙听了一下爱奇艺的Java缓存之路有感写出来的。先简单介绍一下爱奇艺的java缓存道路的发展吧。 可以看见图中分为几个阶段:
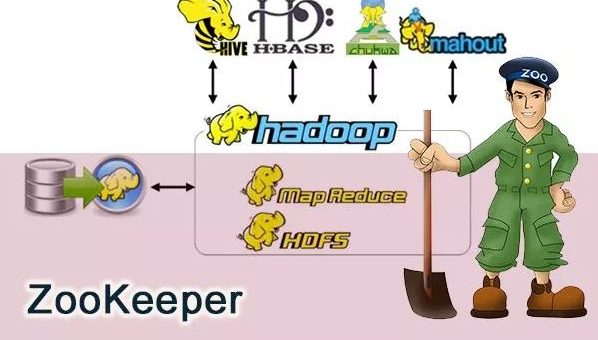
前几天,总结项目经验的时候,我突然问自己 ZooKeeper 到底是个什么东西? 想了半天,脑海中只是简单的能浮现出几句话: Zookeeper 可以被用作注册中心。 Zookeeper 是 Hadoop 生态系统的一员。 构建 Zookeeper 集群的时候,使用的服务器最好是奇数台。 可见,我对于 Zookeeper 的理解仅仅是停留在了表面。所以,通过本文,希望带大家稍微详细的了解一下 ZooKeeper 。 如果没有学过 ZooKeeper,那么本文将会是你进入 ZooKeeper 大门的垫脚砖;如果你已经接触过 ZooKeeper ,那么本文将带你回顾一下 ZooKeeper 的一些基础概念。 最后,本文只涉及 ZooKeeper 的一些概念,并不涉及 ZooKeeper 的使用以及 ZooKeeper 集群的搭建。 网上有介绍...
说到微服务,服务拆分是绕不过去的话题,但是微服务不是说拆就能拆的,有很多的前提条件 1. 服务拆分的前提 服务拆分的前提,首先要有一个持续集成的平台,使得服务在拆分的过程中,保持功能的一致性。 这种一致性不能通过人的经验来,而是需要经过大量的回归测试集,并且持续的拆分,持续的演进,持续的集成,从而保证系统时刻处于可以验证交付的状态。 而非闭门拆分一段时间,最终谁也不知道功能最终究竟有没有 Bug,因而需要另外一个月的时间专门修改 Bug。
在过去两三年的Spring生态圈,最让人兴奋的莫过于Spring Boot框架。或许从命名上就能看出这个框架的设计初衷:快速的启动Spring应用。因而Spring Boot应用本质上就是一个基于Spring框架的应用,它是Spring对“约定优先于配置”理念的最佳实践产物,它能够帮助开发者更快速高效地构建基于Spring生态圈的应用。 那Spring Boot有何魔法?自动配置、起步依赖、Actuator、命令行界面(CLI) 是Spring Boot最重要的4大核心特性,其中CLI是Spring Boot的可选特性,虽然它功能强大,但也引入了一套不太常规的开发模型,因而这个系列的文章仅关注其它3种特性。如文章标题,本文是这个系列的第一部分,将为你打开Spring Boot的大门,重点为你剖析其启动流程以及自动配置实现原理。要掌握这部分核心内容,理解一些Spring框架的基础知识,将会让你事半功倍。
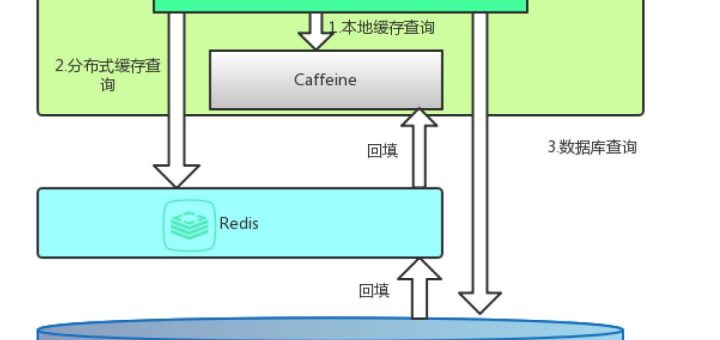
互联网软件神速发展,用户的体验度是判断一个软件好坏的重要原因,所以缓存就是必不可少的一个神器。在多线程高并发场景中往往是离不开cache的,需要根据不同的应用场景来需要选择不同的cache,比如分布式缓存如redis、memcached,还有本地(进程内)缓存如ehcache、GuavaCache、Caffeine。 说起Guava Cache,很多人都不会陌生,它是Google Guava工具包中的一个非常方便易用的本地化缓存实现,基于LRU算法实现,支持多种缓存过期策略。由于Guava的大量使用,Guava Cache也得到了大量的应用。但是,Guava Cache的性能一定是最好的吗?也许,曾经,它的性能是非常不错的。但所谓长江后浪推前浪,总会有更加优秀的技术出现。今天,我就来介绍一个比Guava Cache性能更高的缓存框架:Caffeine。 官方性能比较 Google Guava工具包中的一个非常方便易用的本地化缓存实现,基于LRU算法实现,支持多种缓存过期策略。 EhCache 是一个纯Java的进程内缓存框架,具有快速、精干等特点,是Hibernate中默认的CacheProvider。 Caffeine是使用Java8对Guava缓存的重写版本,在Spring Boot 2.0中将取代,基于LRU算法实现,支持多种缓存过期策略。 场景1:8个线程读,100%的读操作。 场景二:6个线程读,2个线程写,也就是75%的读操作,25%的写操作。 场景三:8个线程写,100%的写操作。 可以清楚地看到Caffeine效率明显高于其他缓存。 如何使用?
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<span class=""> 1</span> public <span class="">static</span> <span class="">void</span> main(<span class="">String</span>[] args) { <span class=""> 2</span> LoadingCache<<span class="">String</span>, <span class="">String</span>> build = CacheBuilder.newBuilder().initialCapacity(<span class="">1</span>).maximumSize(<span class="">100</span>).expireAfterWrite(<span class="">1</span>, TimeUnit.DAYS) <span class=""> 3</span> .build(<span class="">new</span> CacheLoader<<span class="">String</span>, <span class="">String</span>>() { <span class=""> 4</span> <span class="">//默认的数据加载实现,当调用get取值的时候,如果key没有对应的值,就调用这个方法进行加载</span> <span class=""> 5</span> <span class="">@Override</span> <span class=""> 6</span> public <span class="">String</span> load(<span class="">String</span> key) { <span class=""> 7</span> <span class="">return</span> <span class="">""</span>; <span class=""> 8</span> } <span class=""> 9</span> }); <span class="">10</span> } <span class="">11</span> } |
参数方法: initialCapacity(1) 初始缓存长度为1; maximumSize(100) 最大长度为100; expireAfterWrite(1, TimeUnit.DAYS) 设置缓存策略在1天未写入过期缓存(后面讲缓存策略)。 过期策略 在Caffeine中分为两种缓存,一个是有界缓存,一个是无界缓存,无界缓存不需要过期并且没有界限。 在有界缓存中提供了三个过期API: expireAfterWrite:代表着写了之后多久过期。(上面列子就是这种方式)...
1. 一、单系统登录机制 1-1. 1、http无状态协议 web应用采用browser/server架构,http作为通信协议。http是无状态协议,浏览器的每一次请求,服务器会独立处理,不与之前或之后的请求产生关联,这个过程用下图说明,三次请求/响应对之间没有任何联系
考虑到绝大部分写业务的程序员,在实际开发中使用 Redis 的时候,只会 Set Value 和 Get Value 两个操作,对 Redis 整体缺乏一个认知。 所以我斗胆以 Redis 为题材,对 Redis 常见问题做一个总结,希望能够弥补大家的知识盲点。 本文围绕以下几点进行阐述: 为什么使用 Redis 使用 Redis 有什么缺点 单线程的 Redis 为什么这么快 Redis 的数据类型,以及每种数据类型的使用场景 Redis 的过期策略以及内存淘汰机制 Redis 持久化机制 Redis 事务 Redis 和数据库双写一致性问题 如何应对缓存穿透和缓存雪崩问题 如何解决 Redis 的并发竞争 Key 问题 1. 为什么使用 Redis 我觉得在项目中使用 Redis,主要是从两个角度去考虑:性能和并发。 当然,Redis 还具备可以做分布式锁等其他功能,但是如果只是为了分布式锁这些其他功能,完全还有其他中间件,如...
Follow:
![[汇总]端侧模型](https://www.mobabel.net/wp-content/themes/hueman/assets/front/img/thumb-small-empty.png)

| Cookie | Duration | Description |
|---|---|---|
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |